计算百分位数值 P99
平时看一些大佬的性能报告,经常可以看到一些诸如 P99 之类的报告,所以这个 P 是什么意思呢? 99 又是什么意思呢?
下面转载自 P95、P99.9百分位数值——服务响应时间的重要衡量指标
通常,我们对服务响应时间的衡量指标有 Min(最小响应时间)、Max(最大响应时间)、Avg(平均响应时间) 等。
平均值 Avg
其中比较常用的值就是平均值,例如平均耗时为 100ms,表示 服务器当前请求的总耗时 / 请求总数量,通过该值,我们大体能知道服务运行情况。
但是使用平均值来衡量响应时间有个非常大的问题,举个例子:众所周知,我和 Jack马和 tony马的财富加起来足以撼动整个亚洲,我和姚明的平均身高有两米多......
平均值同样有这种问题,这个衡量指标的计算方式会把一些异常的值平均掉,进而会掩盖一些问题,我们只知道所有请求的平均响应时间是 100ms,但是具体有多少个请求比 100ms要大,又有多少个请求比 100ms要小,大多少,是 200ms,还是 500ms,又或是 1000ms,我们无从得知。
百分位数值
平均值并不能反映数据分布及极端异常值的问题,这时我们可以使用百分位数值。
百分位数值是一个统计学中的术语。
如果将一组数据从小到大排序,并计算相应的累计百分位,则某一百分位所对应数据的值就称为这一百分位的百分位数。可表示为:一组 n 个观测值按数值大小排列。如,处于 p% 位置的值称第 p 百分位数
用我们软件开发行业的例子通俗来讲就是,假设有 100 个请求,按照响应时间从小到大排列,位置为 X 的值,即为 PX 值。
P1 就是响应时间最小的请求,P10 就是排名第十的请求,P100 就是响应时间最长的请求。
在真正使用过程中,最常用的主要有 P50(中位数)、P95、P99。
P50: 即中位数值。100 个请求按照响应时间从小到大排列,位置为 50 的值,即为 P50 值。如果响应时间的 P50 值为 200ms,代表我们有半数的用户响应耗时在 200ms 之内,有半数的用户响应耗时大于 200ms。如果你觉得中位数值不够精确,那么可以使用 P95 和 P99.9
P95: 响应耗时从小到大排列,顺序处于 95% 位置的值即为 P95 值。
还是采用上面那个例子,100 个请求按照响应时间从小到大排列,位置为 95 的值,即为 P95 值。 我们假设该值为 200ms,那这个值又表示什么意思呢?
意思是说,我们对 95% 的用户的响应耗时在 200ms 之内,只有 5% 的用户的响应耗时大于 200ms,据此,我们掌握了更精确的服务响应耗时信息。
P99.9: 许多大型的互联网公司会采用 P99.9 值,也就是 99.9% 用户耗时作为指标,意思就是 1000 个用户里面,999 个用户的耗时上限,通过测量与优化该值,就可保证绝大多数用户的使用体验。 至于 P99.99 值,优化成本过高,而且服务响应由于网络波动、系统抖动等不能解决之情况,因此大多数时候都不考虑该指标。
计算百分位数值
平均值之所以会成为大多数人使用衡量指标,其原因主要在于他的计算非常简单。请求的 总耗时 / 请求总数量 就可以得到平均值。而 P 值的计算则相对麻烦一些。
按照传统的方式,计算 P 值需要将响应耗时从小到大排序,然后取得对应百分位之值。
如果服务 qps 较低,例如:100/秒,我们计算这 1s 内的 P 值,就记录这 100 请求的耗时数据,然后排序,然后取得 P 分位值,并非难事。但如果我们要计算 1h 内的 p 值呢,就是要对 360000 的数据进行排序然后取得 P 分位值。而如果对于一些用户量更大的系统,例如:QPS 30万/秒,那么 1h 内的 p 值如果还是 采用记录 + 排序 的方式,就是要对十个多亿的数据进行排序,可想而知需要消耗多么大的内存与计算资源。
那么有没有简单的计算方式呢?
可以采用分桶计算的方式,即一个耗时范围一个桶,该计算方式虽不是完全准确值,但精度非常高,误差较小。
首先需要界定每个桶的跨度,可以采用等分形式,例如对于耗时统计需求,我们可以假定一个耗时上界,然后等分成 N 个区间,如下图,如果响应耗时在 30ms 则落在 0-50ms 的桶内,如果响应时间在 80ms 则落在 50-100ms 的桶内,以此类推。
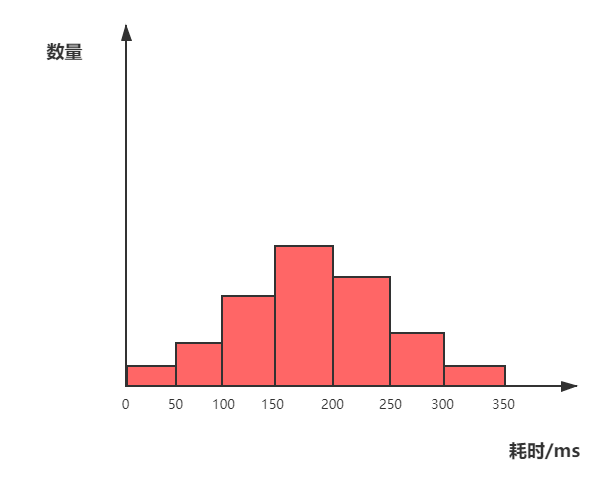
这样就避免了对全部数据进行排序,只需要根据各个桶中的数据数量,即可计算出 95% 位置位于哪个桶,例如需要计算 95 线时,就从最大的桶开始剔除,当数量超过 5% 的时候,那个桶的值就是 95 线。然后在桶的内部采用插值方法,也可以通过桶内平均的方式来计算出一个相对精确的 P95 值。
此外,考虑到数据分布特点,服务耗时异常数据应该只是少数,但是异常值跨度可能很大,大部分耗时数据均靠近正常值,如果采用桶等分的形式,可能会导致大量数据堆积在一个桶内中,又如何解决这个问题?
其实可以采用非等分的跨度划分方式,例如采用指数形式划分,耗时越低的区间,跨度越小,精度约高。

此外也可以采用美团点评的实时监控系统cat的桶跨度划分方式,代码如下:
public static int computeDuration(int duration) {
if (duration < 1) {
return 1;
} else if (duration < 20) {
return duration;
} else if (duration < 200) {
return duration - duration % 5;
} else if (duration < 500) {
return duration - duration % 20;
} else if (duration < 2000) {
return duration - duration % 50;
} else if (duration < 20000) {
return duration - duration % 500;
} else if (duration < 1000000) {
return duration - duration % 10000;
} else {
int dk = 524288;
if (duration > 3600 * 1000) {
dk = 3600 * 1000;
} else {
while (dk < duration) {
dk <<= 1;
}
}
return dk;
}
}
即:小于 20ms 的时候 1ms 一个桶,大于 20ms 小于 200ms 的时候 5ms 一个桶,大于 200ms 小于 500ms 的时候 20ms 一个桶,以此类推!而桶的值也可以作为百分位数的近似值,而无需进行排序计算,这个时候约耗时越小的时候,精度越准确!